<https://i.postimg.cc/d388rqkj/google02.jpg> +1 (650) 253-0000
If you care about either Usenet or the DejaNews DejaGoogle search
engine (which provides links to specific Usenet posts), then...
*Please Do This!*
<https://groups.google.com/g/google-usenet/about>
Which will look like this:
<https://i.postimg.cc/3JzWxG3f/please-do-this.jpg>
The DejaGoogle search engine is useful to everyone (not just us) because:
a. DejaGoogle doesn't require an account or paying for retention
b. DejaGoogle links work for everyone (even your 99 year old mother)
c. DejaGoogle only needs a web browser (which everyone has)
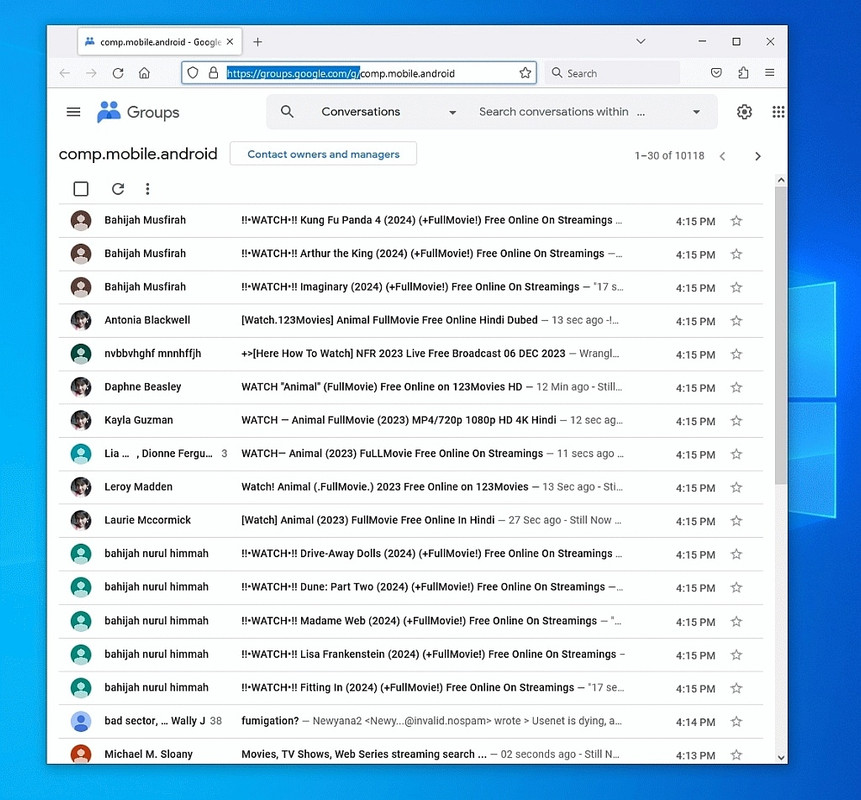
The problem with all this spam from Google servers is that even finding the >URI to an article posted _today_ is a mess of wading through that garbage.
<https://i.postimg.cc/yxpSLVrr/Google-Groups-Usenet-Portal-spam-20231206-730am.jpg>
Details follow...
That is the easiest way (I know of) to complain to Google about
their Google-Groups servers allowing Google Usenet portal spam
(which ruins their own Usenet DejaGoogle search engine output)
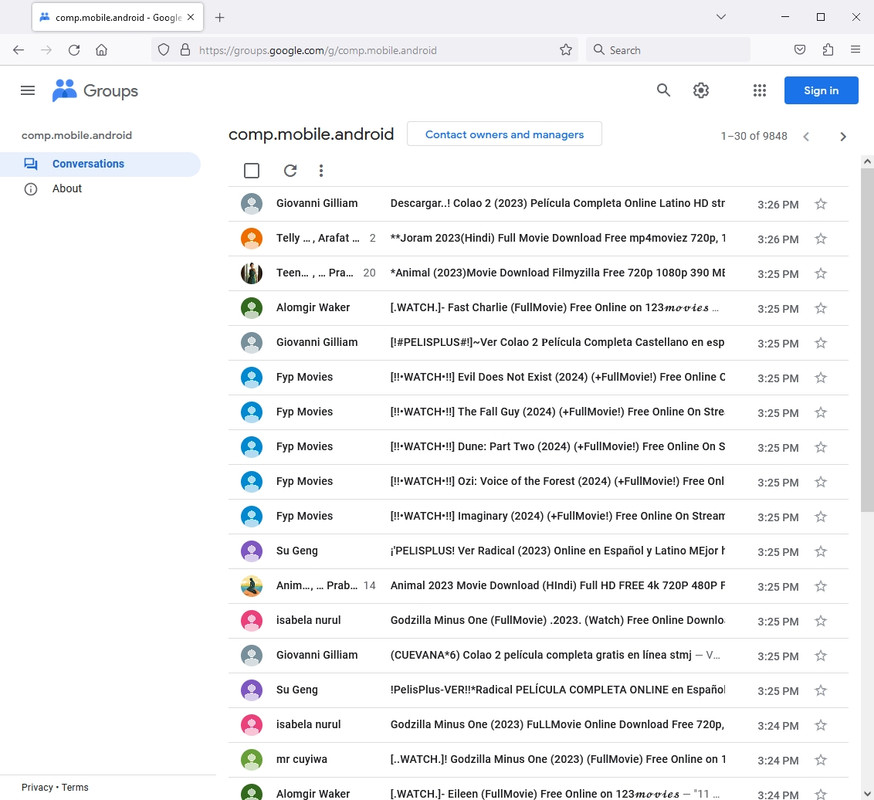
<https://groups.google.com/g/comp.mobile.android>
You're welcome to upload this screenshot showing the problem:
<https://i.postimg.cc/fyCXPjpR/Google-Groups-Usenet-Portal-spam-20231206-730am.jpg>
Together, maybe we can get Google to at least look at the problem we face.
*Please do this today:*
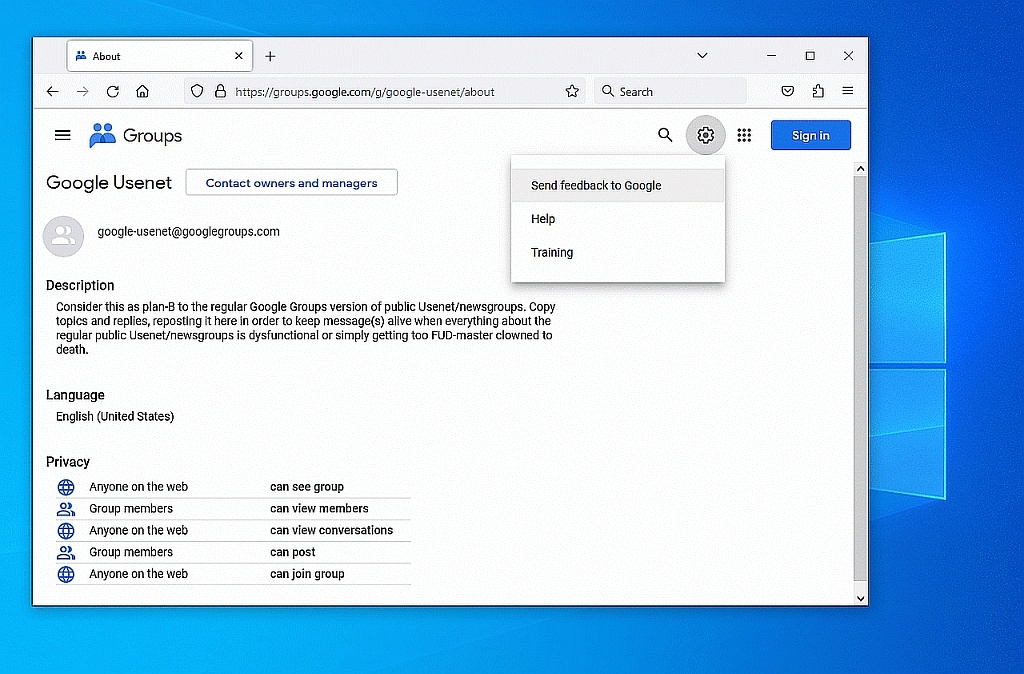
1. Go to <https://groups.google.com/g/google-usenet/about>
2. Click the "Gear" icon at the top right of that web page
3. Select the option to "Send feedback to Google"
Box 1: "Tell us what prompted this feedback."
Box 2: "A screenshot will help us better understand your feedback."
Optionally, you can do the deluxe version of sending feedback to Google.
A. In tab 1, go to <https://groups.google.com/g/comp.mobile.android>
B. Take a screenshot & save it to a date-related name you can easily find.
C. In tab 2, go to <https://groups.google.com/g/google-usenet/about>
D. Click the "Gear" icon at the top right of that "about" web page
E. In the first box "Tell us what prompted this feedback."
tell Google the problem in a way that Google 'may' care about.
For example, tell them something like "Your Google Groups servers
are allowing obvious off-topic rampant spamming by few individuals
<https://groups.google.com>
such that your own Google Groups Server Search Engine
<http://groups.google.com/g/comp.mobile.android>
is now useless because a few users are abusing your Google servers."
F. In the second box upload that screenshot of the first tab.
G. Press the "Send" button on the bottom right of that second tab.
Here's what it looks like, with every step above documented below.
<https://i.postimg.cc/25gytfM9/googlebug1.jpg> <https://i.postimg.cc/sX0KBm6Z/googlebug2.jpg> <https://i.postimg.cc/mgt9kRxV/googlebug3.jpg> <https://i.postimg.cc/Mp2wMbN4/googlebug4.jpg> <https://i.postimg.cc/CLVYdsW-2/googlebug5.jpg> <https://i.postimg.cc/4ysLRySW-/googlebug6.jpg>
In summary, I tried contacting Google to find a better way, to no avail.
<https://i.postimg.cc/kgFknPX0/google01.jpg>
So this online complaint form is the only one that I know about.
<https://groups.google.com/g/google-usenet/about>
If you know of a better way to complain about this, please let us know.
I'm still shocked that Google Groups' Usenet portal allows all this obvious >spam, but if they're going to wipe out the dejanews/dejagoogle search
engine, even the self-centered people who will never understand this
problem set (which is 9,999 out of 1,000) will be adversely affected.
In article <uksoui$1oqca$1@paganini.bofh.team>,snip
Wally J <walterjones@invalid.nospam> wrote:
__________________I'm still shocked that Google Groups' Usenet portal allows all this obvious >>spam, but if they're going to wipe out the dejanews/dejagoogle search >>engine, even the self-centered people who will never understand this >>problem set (which is 9,999 out of 1,000) will be adversely affected.
Google Groups has now made the Dejanews Archive worth less than 1 cent US.
General Information[end quote]
*Deja News Homepage
Learn the ins and outs of the Deja News Homepage.
*New Users
The ideal starting place if this is your first time to Deja News.
*Contacting Us
How to get help via email if you can't find an answer to your question!
Frequently Asked Questions
*Deja News FAQ
A general Frequently Asked Questions about Deja News specific issues.
*Usenet FAQ
Got a question about Usenet in general? Get the FAQs!!
*Posting FAQ
All the FAQs about posting to Deja News.
And More...
*Bookmark Us
How to add Deja News to your hotlist or bookmark file.
*Link to Deja News
Link to Deja News from your Web site!
*Deja News Glossary
Find out more about the terminology most commonly used on the Deja News
site.
Searching[end quote]
How do I search for something?
Deja News is very easy to use (and it's free, of course), so all you have
to do is go to our Quick Search or Power Search page, enter some keywords
and have fun! Please be sure to read our help documents for more advanced search features.
What's the difference between Quick Search and Power Search?
Our Quick Search page will perform a search on our current database
(which is usually the last several weeks of newsgroup articles) matching,
if possible, ALL of your keywords. On our Power Search page, you can customize your search with a variety of sorting options, view older Usenet articles, select a set of articles before searching on keywords, and much more!
That's already something of value, but I don't even know how to do that anymore. I used to. By seeing how the interface changes from time to
time, I gave up on Google Groups even as an archive. I still think we
need a all-time USENET serious archive. I would like to locate any
message by message-id, no matter in which group it was posted. Is that
a dream?
On 12/8/23 21:47, Julieta Shem wrote:
That's already something of value, but I don't even know how to do that
anymore. I used to. By seeing how the interface changes from time to
time, I gave up on Google Groups even as an archive. I still think we
need a all-time USENET serious archive. I would like to locate any
message by message-id, no matter in which group it was posted. Is that
a dream?
I think that finding a collection of all the messages is going to be the biggest hurtle.
I had a collection going back to late 2018 and it was 27 million
articles. Had because I've since removed articles from Google Groups.
So if it's 27 million articles ~5 years, I don't want to fathom what it
would be going back to the '80s.
I strongly suspect much of that data is gone.
I have a little over 20 years of many Usenet hierarchies, 336,216,091 messages, about 1.5TB uncompressed. Using ZFS file system with compression and
CNFS buffers gets it down to ~450GB. It is far from "complete" but I'm working
on it.
Stalled on getting the rest imported from archive.org due storage, but it is on the roadmap (waiting on some some high endurance SSDs).
Between the Uztoo archive, others on archive.org, and what is still available on commercial providers, I believe we have the vast majority of Usenet's history available, but there are bound to be gaps or missing articles throughout any archive.
On 12/8/23 21:47, Julieta Shem wrote:
That's already something of value, but I don't even know how
to do that anymore. I used to. By seeing how the interface
changes from time to time, I gave up on Google Groups even as
an archive. I still think we need a all-time USENET serious
archive. I would like to locate any message by message-id, no
matter in which group it was posted. Is that a dream?
I think that finding a collection of all the messages is going
to be the biggest hurtle.
I'm trying to do the same thing,
On 09/12/2023 14:09, Jesse Rehmer wrote:
I have a little over 20 years of many Usenet hierarchies, 336,216,091
messages, about 1.5TB uncompressed. Using ZFS file system with compression and
CNFS buffers gets it down to ~450GB. It is far from "complete" but I'm working
on it.
Stalled on getting the rest imported from archive.org due storage, but it is >> on the roadmap (waiting on some some high endurance SSDs).
Between the Uztoo archive, others on archive.org, and what is still available
on commercial providers, I believe we have the vast majority of Usenet's
history available, but there are bound to be gaps or missing articles
throughout any archive.
I'm trying to do the same thing, I'll contact you privately to
coordinate efforts, I currently have 24TB of storage waiting to be
filled (I'm currently at 2TB, and the script is continuing to import
from various sources, all the way back to 2000 )
If you have stuff, we can discuss what the best route is.
The hierarchy that is currently giving me the most problems is alt.* as
it is the most "sewer" of all the others.
Sincerely
On 09/12/2023 14:09, Jesse Rehmer wrote:
I have a little over 20 years of many Usenet hierarchies, 336,216,091 >>messages, about 1.5TB uncompressed. Using ZFS file system with
compression and CNFS buffers gets it down to ~450GB. It is far from >>"complete" but I'm working on it.
Stalled on getting the rest imported from archive.org due storage, but it is >>on the roadmap (waiting on some some high endurance SSDs).
Between the Uztoo archive, others on archive.org, and what is still >>available on commercial providers, I believe we have the vast majority
of Usenet's history available, but there are bound to be gaps or missing >>articles throughout any archive.
I'm trying to do the same thing, I'll contact you privately to
coordinate efforts, I currently have 24TB of storage waiting to be
filled (I'm currently at 2TB, and the script is continuing to import
from various sources, all the way back to 2000 )
If you have stuff, we can discuss what the best route is.
The hierarchy that is currently giving me the most problems is alt.* as
it is the most "sewer" of all the others.
I would like to locate any
message by message-id, no matter in which group it was posted. Is that
a dream?
Ivo Gandolfo <usenet@bofh.team> wrote:
On 09/12/2023 14:09, Jesse Rehmer wrote:
I have a little over 20 years of many Usenet hierarchies, 336,216,091
messages, about 1.5TB uncompressed. Using ZFS file system with
compression and CNFS buffers gets it down to ~450GB. It is far from
"complete" but I'm working on it.
Stalled on getting the rest imported from archive.org due storage, but it is
on the roadmap (waiting on some some high endurance SSDs).
Between the Uztoo archive, others on archive.org, and what is still
available on commercial providers, I believe we have the vast majority
of Usenet's history available, but there are bound to be gaps or missing >>> articles throughout any archive.
I'm trying to do the same thing, I'll contact you privately to
coordinate efforts, I currently have 24TB of storage waiting to be
filled (I'm currently at 2TB, and the script is continuing to import
from various sources, all the way back to 2000 )
If you have stuff, we can discuss what the best route is.
The hierarchy that is currently giving me the most problems is alt.* as
it is the most "sewer" of all the others.
This shouldn't be available on line where Google can index it. It makes
it painful to search for Usenet articles as so much other stuff from the
Web comes up. Similarly, if I'm searching the Web, normally I don't want Usenet articles coming up.
Plenty of Usenet shouldn't be archived. Too many newsgroups are nothing
but reposts of articles from the Web whose true author had not posted
them to Usenet. That's plagarism.
Also I think some of the longest-running flame wars -- going back three decades as someone pointed out the other day -- are cron jobs.
There never has been a lot on Usenet that shouldn't be ephemeral.
1) Some news servers have over 20 years of text retention and over
15 years of binary retention.
[...]
Plenty of Usenet shouldn't be archived. [...]
There never has been a lot on Usenet that shouldn't be ephemeral.
Le 09/12/2023 19:57, Ralph Fox a �crit :
1) Some news servers have over 20 years of text retention and over
15 years of binary retention.
That is way too much! The nntp server that I use has one month of text retention, which is consistent with the notion of � news � (not � olds �)
Olivier Miakinen <om+news@miakinen.net> wrote:
Le 09/12/2023 19:57, Ralph Fox a �crit :
1) Some news servers have over 20 years of text retention and over
15 years of binary retention.
That is way too much! The nntp server that I use has one month of text
retention, which is consistent with the notion of � news � (not � olds �)
The context - Julieta Shem's questions - was archives. For archives, a month of retention is useless.
FYI, because there are no good - searchable - Usenet archives, I keep
my own archive, for my selected/subscribed groups and largely filtered
on trolls, spam, kooks, etc.. My retention is nearly 20 years.
Yes, it is ok for archives, accessible via the web. But some news servers
have up to one year accessible by NNTP, or even more. And IMHO *that* is
way too much (though I know that my opinion is not widely shared).
If it's okay for an archive to have ~20 years of retention and it's okay
for an archive to be accessible via the web (HTTP(S)), why is it not
also okay for the archive to be accessible via NNTP(S).
Yes, it is ok for archives, accessible via the web. But some news servers have up to one year accessible by NNTP, or even more. And IMHO *that* is
way too much (though I know that my opinion is not widely shared).
FYI, because there are no good - searchable - Usenet archives, I keep
my own archive, for my selected/subscribed groups and largely filtered
on trolls, spam, kooks, etc.. My retention is nearly 20 years.
Ok for that.
Maybe I have a bad newsreader or I don't know how to use it ?
The fact is, when I have to look for a given topic, and I register to
the corresponding newsgroup, it takes me a lot of time to read the
whole newsgroup when there are several months (or years) of retention
on the server.
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101
Firefox/52.0 SeaMonkey/2.49.4
Maybe I have a bad newsreader or I don't know how to use it ?
The fact is, when I have to look for a given topic, and I register to
the corresponding newsgroup, it takes me a lot of time to read the
whole newsgroup when there are several months (or years) of retention
on the server.
On 09/12/2023 14:09, Jesse Rehmer wrote:
I have a little over 20 years of many Usenet hierarchies, 336,216,091
messages, about 1.5TB uncompressed. Using ZFS file system with
compression and CNFS buffers gets it down to ~450GB. It is far from
"complete" but I'm working on it. Stalled on getting the rest
imported from archive.org due storage, but it is on the roadmap
(waiting on some some high endurance SSDs). Between the Uztoo
archive, others on archive.org, and what is still available on
commercial providers, I believe we have the vast majority of Usenet's
history available, but there are bound to be gaps or missing articles
throughout any archive.
I'm trying to do the same thing, I'll contact you privately to
coordinate efforts, I currently have 24TB of storage waiting to be
filled (I'm currently at 2TB, and the script is continuing to import
from various sources, all the way back to 2000 )
If you have stuff, we can discuss what the best route is.
The hierarchy that is currently giving me the most problems is alt.*
as it is the most "sewer" of all the others.
Ivo Gandolfo <usenet@bofh.team> writes:
On 09/12/2023 14:09, Jesse Rehmer wrote:
I have a little over 20 years of many Usenet hierarchies, 336,216,091
messages, about 1.5TB uncompressed. Using ZFS file system with
compression and CNFS buffers gets it down to ~450GB. It is far from
"complete" but I'm working on it. Stalled on getting the rest
imported from archive.org due storage, but it is on the roadmap
(waiting on some some high endurance SSDs). Between the Uztoo
archive, others on archive.org, and what is still available on
commercial providers, I believe we have the vast majority of Usenet's
history available, but there are bound to be gaps or missing articles
throughout any archive.
I'm trying to do the same thing, I'll contact you privately to
coordinate efforts, I currently have 24TB of storage waiting to be
filled (I'm currently at 2TB, and the script is continuing to import
from various sources, all the way back to 2000 )
If you have stuff, we can discuss what the best route is.
The hierarchy that is currently giving me the most problems is alt.*
as it is the most "sewer" of all the others.
You two have my respect. That's a pretty serious project. The USENET >carries principles such as decentralization and censorship resistance.
And likely way more important than that is the principles of >self-organization that might be the only real promise of any social >organization.
FYI, because there are no good - searchable - Usenet archives, I keep
my own archive, for my selected/subscribed groups and largely filtered
on trolls, spam, kooks, etc.. My retention is nearly 20 years.
On Sun, 10 Dec 2023 02:29:07 -0300
Julieta Shem <jshem@yaxenu.org> wrote:
Trimming the destinataries to news.admin.net-abuse.usenet only.
Wally J <walterjones@invalid.nospam> writes:
Julieta Shem <jshem@yaxenu.org> wrote
I would like to locate any message by message-id, no matter in
which group it was posted. Is that a dream?
You didn't mention whether or not you already know the message id.
If you already know it, what's wrong with the Howard Knight site?
<http://al.howardknight.net/>
I had never heard of this website. It's asking me for a username and
password, which I don't have. It also presenting a certificate issued
to a different hostname.
The username and password stuff was news to me and seems to be the case if you go to https://al.howardknight.net .But if you go to http://al.howardknight.net/ , there's none of that stuff.
On Sat, 9 Dec 2023 20:40:28 +0100
Le 09/12/2023 20:28, Frank Slootweg a écrit :
Yes, it is ok for archives, accessible via the web. But some news servers
have up to one year accessible by NNTP, or even more. And IMHO *that* is
way too much (though I know that my opinion is not widely shared).
Count me among those who do not share your opinion. As far as I'm concerned , the longer retention there is , the better.
Frank Slootweg <this@ddress.is.invalid> wrote:
FYI, because there are no good - searchable - Usenet archives, I keep
my own archive, for my selected/subscribed groups and largely filtered
on trolls, spam, kooks, etc.. My retention is nearly 20 years.
And from my perspective, 20 years only goes back to 2003 when Usenet was already on the way down. I'd like to see maybe 1983 to 2010 and I don't
much care about anything after then.
Guys like Larry Lippman and Bill Vermillion left a lot of really useful posts. They are now deceased and all that information is lost.
Sure, but, assuming we have a ``complete'' archive somewhere, a sysadmin
with few resources could run a thin server and these thin users could
have a smart client that whenever we would like to fetch a nonexistent article we would ask the archive.
Say I'm reading a post and I'd like to take a look at its parent, which
has been expired. My client asks Howard Knight, fetches a copy and I'm
good. So an archive with an API for fetching raw articles is a pretty
nice service.
I care about that too. There's history, too. Say we're talking about
the birth of the GNU system. Why can't we cite the message-id of the of
the post by Richard Stallman?
What's sad is that keeping a service
online on the Internet is never an easy job --- there's attacks and
whatnot. I wish I could put a well set-up service online and turn my
back on it forever. But that's a dream I could never realize.
The lack of access to the latter from any source at all.
I mean, I can
cite the article (if I could find it), but there is no point in citing something that nobody can read.
Dejanews provided exactly what was asked for, and so did Google for a
while, until they "improved" things to the point where it was completely broken.
Committing the resources is an issue, but not the big one.
The real problem is availability of the data.
When dejanews was created an enormous amount of
effort went into finding pre-dejanews material and passing it off to dejanews.
At this point, most of that likely no longer exists except in google's database. And there's no point in it being in there if people can't find it.
On 12/10/23 10:51, Julieta Shem wrote:
I care about that too. There's history, too. Say we're talking about
the birth of the GNU system. Why can't we cite the message-id of the of
the post by Richard Stallman?
I believe you can.
What is different about citing an article from yesterday vs an article
from 25 years ago /other/ /than/ lack of the latter on the news server
you're using?
I believe that current methodologies can provide what is being asked for
if the data was available and people were willing to commit the
resources for it.
Frank Slootweg <this@ddress.is.invalid> wrote:
FYI, because there are no good - searchable - Usenet archives, I keep
my own archive, for my selected/subscribed groups and largely filtered
on trolls, spam, kooks, etc.. My retention is nearly 20 years.
And from my perspective, 20 years only goes back to 2003 when Usenet was already on the way down. I'd like to see maybe 1983 to 2010 and I don't
much care about anything after then.
Guys like Larry Lippman and Bill Vermillion left a lot of really useful posts. They are now deceased and all that information is lost.
You didn't mention whether or not you already know the message id.
If you already know it, what's wrong with the Howard Knight site?
<http://al.howardknight.net/>
I had never heard of this website. It's asking me for a username and password, which I don't have. It also presenting a certificate issued
to a different hostname.
Julieta Shem wrote
You didn't mention whether or not you already know the message id.
If you already know it, what's wrong with the Howard Knight site?
<http://al.howardknight.net/>
I had never heard of this website. It's asking me for a username and
password, which I don't have. It also presenting a certificate issued
to a different hostname.
I'm sorry about that.
I care that you get your answer that you need.
But I didn't respond at first as I have nothing more to help you with.
Nobody else has responded to this, unfortunately.
So let's home someone else can help you explain what is happening.
Especially as it purports to do exactly what it is you asked for.
To be clear, I can't explain your results as when I go to howardknight.net, it only asks me for the message id. But I'm just a long-time user.
I'm not an admin in any way.
All we can do to help is ask the others here why Howardknight.net would ask for a password from you - when it has never asked for a password from me.
On 12/10/23 10:37, Julieta Shem wrote:
Sure, but, assuming we have a ``complete'' archive somewhere, a sysadmin
with few resources could run a thin server and these thin users could
have a smart client that whenever we would like to fetch a nonexistent
article we would ask the archive.
I question the veracity of "few resources".
I'm seeing 5+ million articles per year in my short (5+ year)
archive. -- Those numbers might not stay the same, but they are a
starting point for this discussion.
If we say ~5 million articles per year going back 30+ years, that's
150 million messages. That's not just a "few resources" to make
accessible in relatively short order.
Say I'm reading a post and I'd like to take a look at its parent, which
has been expired. My client asks Howard Knight, fetches a copy and I'm
good. So an archive with an API for fetching raw articles is a pretty
nice service.
We already have an API for fetching articles from a server. Network
News Transfer Protocol does perfectly adequate job at it. NNTP is
also already very well supported in most news clients. So why not use
it?
I think what you are after is an NNTP server that has an extremely
deep (30+ year) history.
There may be some room for added complexity in the servers so that
they can look up an old article somewhere else outside of their
corpus. But that's a different problem for a different day.
I believe that an NNTP server meant for archive access and doesn't
allow posting could provide what you're after /if/ such a corpus could
be put together and such a system could be hosted somewhere (and
likely supported by it's user base).
Eh ... given Google's propensity to not get rid of things, I sort of
suspect that the old DeJa News archive is probably still exists
somewhere. It may actually be directly behind Google Groups Usenet
gateway and the gateway itself may be munging articles as they are
presented. Google really is antithetical to destroying data. Getting
to that data, that's an entirely different issue.
On 12/10/23 11:23, Scott Dorsey wrote:
The lack of access to the latter from any source at all.
ACK
I mean, I can
cite the article (if I could find it), but there is no point in citing
something that nobody can read.
I think there is some value in saying something and saying where it
came from. It offers a modicum of veracity and enables the reader to
fact check. What the reader does and does not have access to is not
your primary problem. Though it does behoove you to cite sources that
you know the reader has access to.
INN's traditional spool directories are going to tax just about any
file system when you try to put hundreds of thousands of files in a
single directory. Some newsgroups will have significantly more
articles than others.
Sure, there are ways to store articles so that they aren't all in one directory. But that's now a news server change. It can happen, but
it's not as simple as a configuration change. It will likely be a
code and a configuration change.
There are other message stores, but the ones that I'm aware of tend to
by cyclical in nature and of a fixed size which is antithetical to the archive forever goal.
This is probably a case for a custom NNTP server that is really a
gateway (of sorts) to some sort of object store that is distributed
and designed to scale to millions of
Julieta Shem <jshem@yaxenu.org> wrote
You didn't mention whether or not you already know the message id.
If you already know it, what's wrong with the Howard Knight site?
<http://al.howardknight.net/>
I had never heard of this website. It's asking me for a username and
password, which I don't have. It also presenting a certificate issued
to a different hostname.
I'm sorry about that.
I care that you get your answer that you need.
But I didn't respond at first as I have nothing more to help you with.
Nobody else has responded to this, unfortunately.
So let's home someone else can help you explain what is happening.
Especially as it purports to do exactly what it is you asked for.
To be clear, I can't explain your results as when I go to howardknight.net, it only asks me for the message id. But I'm just a long-time user.
I'm not an admin in any way.
All we can do to help is ask the others here why Howardknight.net would ask for a password from you - when it has never asked for a password from me.
I think the necessary resources are going to be a bigger issue than many other people.
INN's traditional spool directories are going to tax just about any file system when you try to put hundreds of thousands of files in a single directory. Some newsgroups will have significantly more articles than others.
Sure, there are ways to store articles so that they aren't all in one directory. But that's now a news server change. It can happen, but
it's not as simple as a configuration change. It will likely be a code
and a configuration change.
There are other message stores, but the ones that I'm aware of tend to
by cyclical in nature and of a fixed size which is antithetical to the archive forever goal.
This is probably a case for a custom NNTP server that is really a
gateway (of sorts) to some sort of object store that is distributed and designed to scale to millions of objects in a container (newsgroup).
Whatever is done needs to be flexible and have the ability to be
reconfigured as things grow. It should also have a little bit of
redundancy as the more systems that are added to it, the more fragile it
will become.
The real problem is availability of the data.
I agree that's probably the /primary/ problem and supersedes the storage
in such as I believe that computer science / systems people can overcome
the problem mentioned above. -- I'm not as confident that we can
recover a full archive of Usenet any more. After all, according to Wikipedia, we're talking about 43+ years of data. Much of that data was deemed ephemeral by most people. Much of that data was difficult to
collect 20+ years ago. The intervening 20 years won't have helped the matter.
Sure. I cite these messages when I need to. But people often wonder
--- how can I get it? Sometimes there is an answer such as some
website, but such websites scramble over the years.
The USENET deserves the highest standard in archiving.
ACK. When you said NNTP, I said --- okay ---, but I would think that a
whole new system should be set-up.
I would think that archive.org would
be interested in getting a proposal for something like that. They seem pretty serious about archiving the Internet.
Sadly, this could be true, but I feel optimistic about it. If we could
get people's attention, I believe some people would show up saying ---
oh, hey, I got a lot of data here and there and the whole thing would
appear.
I totally bet on the same.
I agree. It's in there, but we can't get it out, and that is the
most frustrating thing possible. We gave it to them, but we can't
it it back.
I meant a sysadmin with little money.
That makes sense --- an NNTP made to be used as as reference, optimized
only to provide a message per message-id.
We should also have a solution for keeping addresses for a very long
time.
In the same way we have organized ourselves to keep the USENET
rolling, we should also organize ourselves to make things last.
But that's seems less easy. When there is money involved, people set
up institutions that keep things going. We should have things like that.
Could a sum of money be allocated, providing interest with which we can
keep basic things like a hostname so that
nntp://arxiv.use.net/<message@id>
always fetches the article with <message@id>?
I think that's the chance
we have of running things properly in the world.
The representative
idea is likely at the end of its time now, finally. Electronic
communication and the electronic printing press might give us the means
to run stuff ourselves now. (An interesting keyword --- sortition.)
I have 1.6TB of tradspool on NVMe and no performance issues. Some groups have over 4 million articles.
You can set CNFS buffers to be written to sequentially, and as long as you're paying attention you can add new buffers without ever losing anything and wrapping to the beginning of the metabuffer. I've experimented with 100GB and 1TB buffer files and performance doesn't seem to matter the CNFS buffer size.
On a ZFS filesystem with CNFS buffers I get roughly 2.86X compression so that 1.6TB of tradspool shrinks down to ~450GB of CNFS buffers.
If one wants to dabble in distributed NNTP architecture, Diablo and its accompanying dreaderd are the way to go. Or NNTPSwitch if you can get it to compile on anything.
I believe we have every bit of Usenet (may not *every single article* but close) with all of the archives on archive.org, and what is still available on
commercial Usenet spools (most go back ~20 years for text retention).
It's a matter of putting it all back together on a usable NNTP spool that's not as easy, but not undoable.
There are a few of us working on projects of our own with the same goal.
On 12/10/23 19:04, Scott Dorsey wrote:
I agree. It's in there, but we can't get it out, and that is the
most frustrating thing possible. We gave it to them, but we can't
it it back.
Having a better idea than many how Google lawyercats behave, I suspect
they would say "you didn't give it to us" and / or "we bought the
company and the data they had". They likely feel zero obligation to
provide it.
Then there's the "you gave X number of articles to the free global
Usenet out of the Y total articles therein" where X is significantly
smaller than Y and as such you get an infinitesimally small part back,
if that.
Scott Dorsey <kludge@panix.com> wrote
I haven't looked extensively but they don't seem to be spamming groups
(such as the Windows 10 and 11 newsgroups most people post to) which aren't >auto-archived - but that could also be because the Google-to-Usenet portal >might not work for groups that aren't part of the DejaNews archives.
Dunno what they're doing for real, but it's only some newsgroups.
Not all.
BTW, on the Android newsgroup some of us are discussing WHY they're doing
all this spam, where not every newsgroup is being spammed, it seems.
These are:
<https://groups.google.com/g/alt.internet.wireless> <https://groups.google.com/g/alt.comp.microsoft.windows> <https://groups.google.com/g/uk.telecom.mobile> <https://groups.google.com/g/rec.photo.digital> <https://groups.google.com/g/alt.home.repair> <https://groups.google.com/g/comp.mobile.android>
etc.
These are not:
<http://alt.comp.os.windows-10.narkive.com> <http://alt.comp.os.windows-11.narkive.com> <https://groups.google.com/g/comp.mobile.ipad> <https://groups.google.com/g/misc.phone.mobile.iphone>
etc.
Let's try it without the enclosing angle brackets.
rather than feed the google monster or other "sanitized" web links, this format is more user-friendly because it invites the reader to browse any
of these aforecited newsgroups using their favorite default newsreaders
<news:comp.mobile.android>
On 12/13/23 09:22, Grant Taylor wrote:
Let's try it without the enclosing angle brackets.
Nope. :-(
That used to work in Thunderbird.
But, Thunderbird is becoming worse at what it does year after year.
BTW, regarding the message from Individual.net, I was heartened they care. >>> Anybody have any new datapoints from Giganews & Highwinds admins yet?
IMHO Individual.net is run by an individual, much like most of the text
only Usenet servers. Both GigaNews and HighWinds are commercial
entities and likely don't care unless one of their paying users complains.
The 'paying customers' of GigaNews & HighWinds seem to be all spammers. ;->
Maybe I have a bad newsreader or I don't know how to use it ?
The fact is, when I have to look for a given topic, and I register to
the corresponding newsgroup, it takes me a lot of time to read the
whole newsgroup when there are several months (or years) of retention
on the server.
by content, likely a significant percentage; but by quasi-randomized crossposting en masse, why any server allows more than three (3) per
article (xpost %>3) seems unreasonable to say the least; it's simple
to forward all or part of an article to another newsgroup (fw:) with reference headers intact where such content may be topical elsewhere;
if every server would limit crossposting that alone might help a lot
In article <ulbhfc$sbm$1@tncsrv09.home.tnetconsulting.net>,
Grant Taylor <gtaylor@tnetconsulting.net> wrote:
On 12/12/23 19:38, Wally J wrote:
BTW, on the Android newsgroup some of us are discussing WHY they're doing >>> all this spam, where not every newsgroup is being spammed, it seems.
I'm of the opinion that it's a bunch of different spam campaigns, likely
by almost as many spammers.
If this is the case, and it's possible, first thing is that they are using >the same script to do it. And secondly, they all are dumping stuff with
the intention of being disruptive rather than the intention of gimmicking >search engines. I suspect initially they were trying to get search engine >results up, but at this point they are just intending to be destructive.
This is why I suspect it's more likely to be one spammer, but I am not >positive.
--scott
On Thu, 14 Dec 2023 09:37:53 -0400, Wally J <walterjones@invalid.nospam> wrote:
I've been on Usenet for as long as anyone
the beauty is that no newsreader is needed
D <remailer@domain.invalid> wrote:
On Thu, 14 Dec 2023 09:37:53 -0400, Wally J <walterjones@invalid.nospam> wrote:
I've been on Usenet for as long as anyone
the beauty is that no newsreader is needed
Using a newsreader, dedicated, fast, native software with a unified
user experience for all groups, instead of anything running in a
browser, is the biggest single advantage that Usenet has over web
forums.
From: Wally J <walterjones@invalid.nospam>^^^ ^^^^^^ ^^ ^^^^ ^^ ^^^^^^^^^^ ^^ ^^^^^^
Newsgroups: comp.mobile.android,news.admin.peering,news.admin.net-abuse.usenet >Subject: Re: Please complain to Google about their spamming of Usenet
Date: Wed, 13 Dec 2023 21:41:59 -0400
Message-ID: <uldmh6$3kas6$1@paganini.bofh.team>
...
The beauty is that no newsreader is needed
D <remailer@domain.invalid> wrote:
On Thu, 14 Dec 2023 09:37:53 -0400,
Wally J <walterjones@invalid.nospam> wrote:
I've been on Usenet for as long as anyone
the beauty is that no newsreader is needed
Quite. The oldest poasters need no 'reader,
they just climb a clock tower and spout.
D <remailer@domain.invalid> wrote:
On Thu, 14 Dec 2023 09:37:53 -0400, Wally J <walterjones@invalid.nospam> wrote:
I've been on Usenet for as long as anyone
the beauty is that no newsreader is needed
Using a newsreader, dedicated, fast, native software with a unified
user experience for all groups, instead of anything running in a
browser, is the biggest single advantage that Usenet has over web
forums.
D <remailer@domain.invalid> wrote:
On Thu, 14 Dec 2023 09:37:53 -0400, Wally J<walterjones@invalid.nospam> wrote:
I've been on Usenet for as long as anyone
the beauty is that no newsreader is needed
Using a newsreader, dedicated, fast, native software with a unified
user experience for all groups, instead of anything running in a
browser, is the biggest single advantage that Usenet has over web
forums.
On Thu, 14 Dec 2023 09:37:53 -0400, Wally J <walterjones@invalid.nospam> wrote:
I've been on Usenet for as long as anyone
the beauty is that no newsreader is needed
D <remailer@domain.invalid> wrote:
On Thu, 14 Dec 2023 09:37:53 -0400,
Wally J <walterjones@invalid.nospam> wrote:
I've been on Usenet for as long as anyone
the beauty is that no newsreader is needed
Quite. The oldest poasters need no 'reader,
they just climb a clock tower and spout.
D <remailer@domain.invalid> wrote:<walterjones@invalid.nospam> wrote:
On Thu, 14 Dec 2023 09:37:53 -0400, Wally J
I've been on Usenet for as long as anyone
the beauty is that no newsreader is needed
Using a newsreader, dedicated, fast, native software with a unified
user experience for all groups, instead of anything running in a
browser, is the biggest single advantage that Usenet has over web
forums.
Well said. The web is somehow not the right thing.
The Doctor <doctor@doctor.nl2k.ab.ca> wrote
This banner is now appearing on Google GRoups
Yeah. I noticed it too and posted this thread about it.
*Effective February 15, 2024, Google Groups will no longer support new Usenet content*
<https://groups.google.com/g/news.admin.peering/c/_w1mbwzgzs0>
What that means is:
a. The ability to search before asking, will be greatly diminished.
b. The ability to reference a URI to a thread or post will disappear.
c. The ability for non-Usenet folks to "read" Usenet will go away too
Sigh.
Maybe we asked for too much from Google?
This banner is on Google GRoups
On Dec 14, 2023 at 5:23:50 PM CST, "Wally J" <walterjones@invalid.nospam> >wrote:
The Doctor <doctor@doctor.nl2k.ab.ca> wrote
This banner is now appearing on Google GRoups
Yeah. I noticed it too and posted this thread about it.
*Effective February 15, 2024, Google Groups will no longer support new Usenet
content*
<https://groups.google.com/g/news.admin.peering/c/_w1mbwzgzs0>
What that means is:
a. The ability to search before asking, will be greatly diminished.
b. The ability to reference a URI to a thread or post will disappear.
c. The ability for non-Usenet folks to "read" Usenet will go away too
Sigh.
Maybe we asked for too much from Google?
[removed irrelevant newsgroups]
Well, everyone kept screaming "depeer Google"... and they're doing it. Now >people will be pissed about that too, I guess.
doctor@doctor.nl2k.ab.ca (The Doctor) writes:
This banner is on Google GRoups
Yes, we read you the first time! Four times in as many minutes, in the
same thread? Seriously...
| Sysop: | Keyop |
|---|---|
| Location: | Huddersfield, West Yorkshire, UK |
| Users: | 307 |
| Nodes: | 16 (2 / 14) |
| Uptime: | 61:51:54 |
| Calls: | 6,915 |
| Files: | 12,379 |
| Messages: | 5,431,371 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}