[continued from previous message]
population. Clearly R0 is larger in some parts of the state and of society
than others.
Even if R0 < 1, outbreaks can be surprisingly large. Suppose you meet 10
people while you are contagious, and you infect each one with a probability
of 8 percent. The average number of people you infect is 10×0.08 = 0.8, less than 1. But those you infect may infect others in turn, and so on. If an outbreak starts with you, how many "descendants" will you have? A classic calculation shows that, if R0= 0.8, then the average number of people in
this chain reaction is 1/(1 - 0.8) = 1/0.2 = 5. But, like R0 itself, this is only an average. Like earthquakes and forest fires, outbreaks have a "heavy tail" where large events are common.
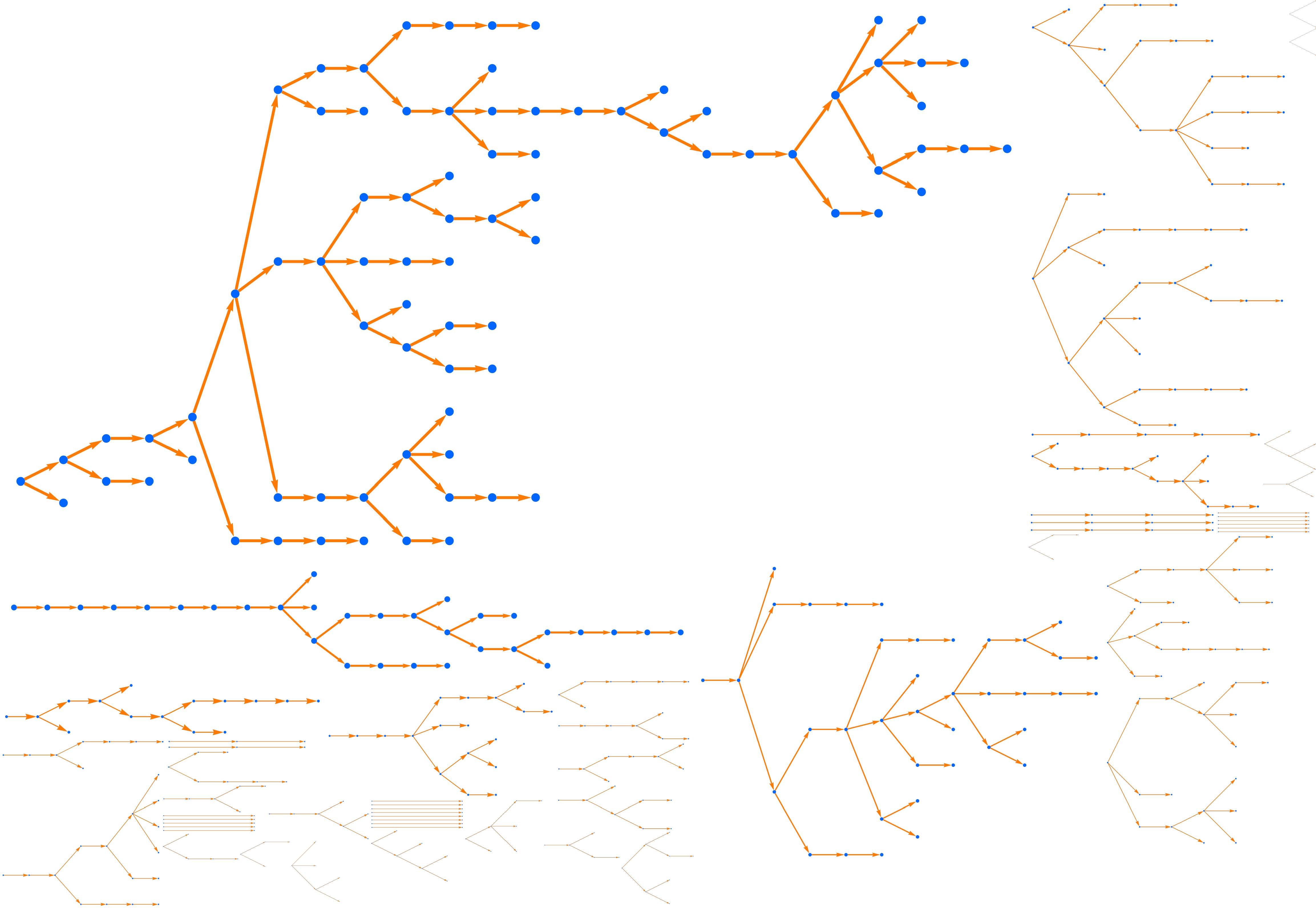
Here is a visualization of 100 random outbreaks. The average size is indeed
5, and most outbreaks are small. But about 1 percent of those outbreaks have size 50 or more, ten times the average, and in this simulation the largest
of these 100 outbreaks has size 82. This tail gets heavier if R0 is just
below the phase transition at R0 = 1. If R0=0.9, the average outbreak size
is 10, but 1 percent have size 140 or more.
https://sfi-edu.s3.amazonaws.com/sfi-edu/production/uploads/ckeditor/2020/04/23/moore_outbreak-fig1-82.jpg
Figure 1. A hundred random outbreaks in a scenario where each sick person interacts with 10 others, and infects each one with probability 8
percent. Here R0 = 0.8 and the average outbreak size is five, but 1 percent
of the outbreaks have size 50 or larger, and in this run the largest has
size 82.
This tail has real effects. Imagine 100 small towns, each with a hospital
that can handle 10 cases. If every town has the average number of cases,
they can all ride out the storm. But there's a good chance that one of them will have 50 or 100, creating a "hot spot" beyond their ability to respond.
The tail of large events gets even heavier if we add superspreading. We
often talk of "superspreaders" as individuals with higher viral loads, or
who by choice or necessity interact with many others. But it's more accurate
to talk about superspreading events and situations -- like the Biogen
meeting, the chorus rehearsal, or the pork processing plant, as well as
prisons and nursing homes -- where the virus may have infected many of those present.
Suppose that 20 percent of cases generate one new case, 10 percent generate
2, 4 percent generate 5, and 1 percent "superspread" and generate 20 (and
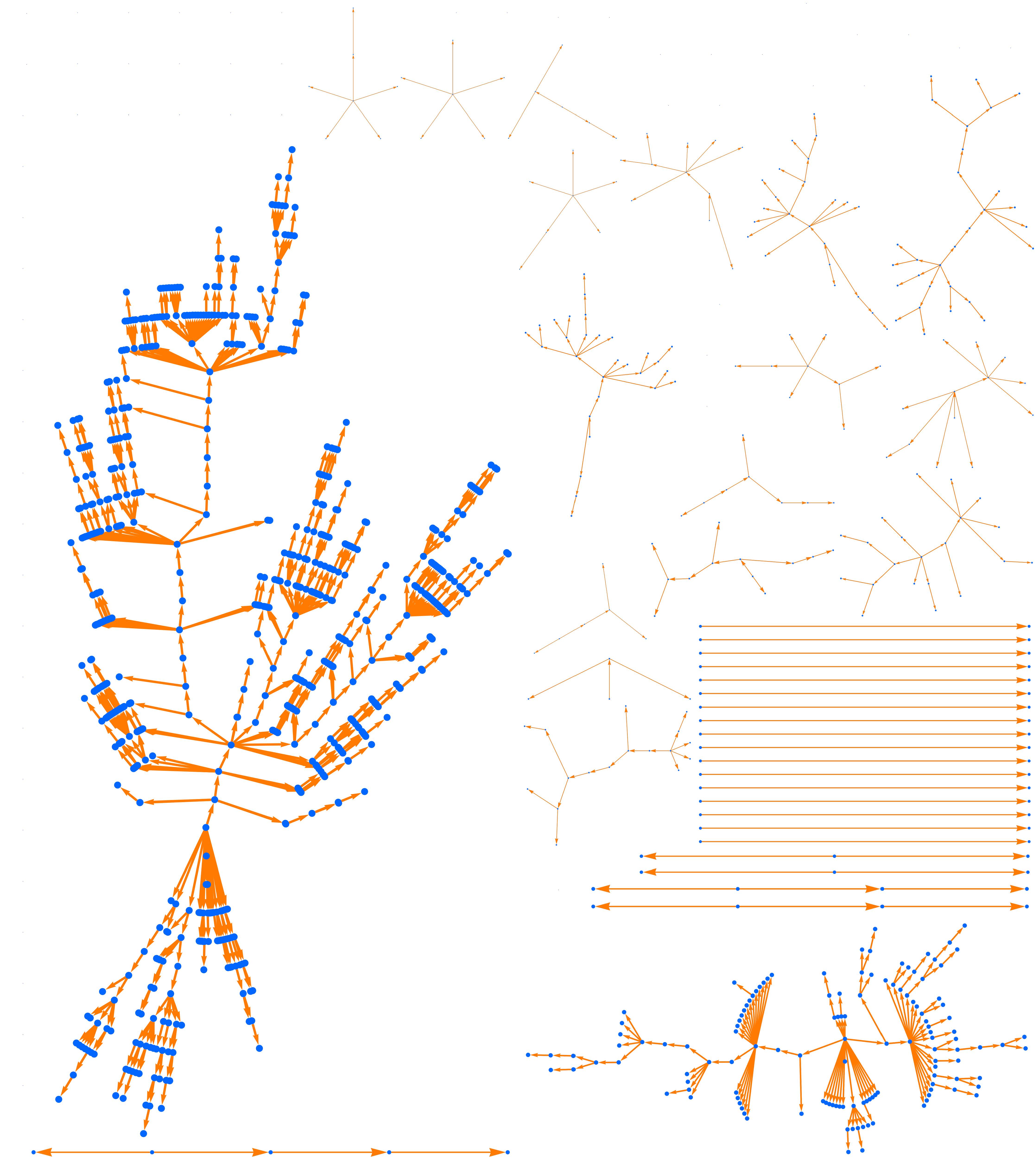
the remaining 65 percent infect no one). The average number of new cases is again R0= 0.8. Let's generate 100 random outbreaks with this new scenario.
https://sfi-edu.s3.amazonaws.com/sfi-edu/production/uploads/ckeditor/2020/04/23/moore_outbreaks-fig2-663.jpg
Figure 2. A hundred random outbreaks in a scenario with superspreading,
where 1 percent of the cases infect 20 others. As in Figure 1, we have R0 =
0.8 and the average outbreak size is 5, but now the heavy tail of outbreaks
is much heavier. In this run the largest outbreak has size 663.
The average outbreak size is still 5, but now the tail is much heavier. If
just one of the 100 original cases is involved in superspreading, we get a large outbreak. If there are several generations of superspreading, the size multiplies. As a result, large outbreaks are quite common, and the largest
one in this simulation has 663 people in it.
What does all this mean? First, it can be misleading to look at
statewide or national averages and celebrate if R0 seems to be falling
below 1. The epidemic could still be raging in particular places or
among particular groups.
Second, even if R0 is below 1, we need to prepare for hot spots. Even if the average outbreak is small, large outbreaks will occur due to superspreading
or simply by chance. If we do a fantastic job at testing and contact tracing
-- using both technology and human effort -- we will get this pandemic under control, but for the foreseeable future there will be times and places where
it flares up and strains local resources. And through those flare-ups, we
have to do our best to help each other, and hope that intelligent, generous voices prevail.
Cristopher Moore, Santa Fe Institute
REFERENCES
Laurent Hébert-Dufresne, Benjamin M. Althouse, Samuel V. Scarpino, and Antoine Allard, "Beyond R0: Heterogeneity in secondary infections and probabilistic epidemic forecasting."
https://arxiv.org/abs/2002.04004
J. O. Lloyd-Smith, S. J. Schreiber, P. E. Kopp, and W. M. Getz, "Superspreading and the effect of individual variation on disease emergence." Nature 438 (2005) 355–359.
T-024 (Moore) PDF
https://sfi-edu.s3.amazonaws.com/sfi-edu/production/uploads/ckeditor/2020/04/27/t-024-moore.pdf
Read "Coronavirus Doesn't Care About Your Data Points" in Bloomberg (May 11, 2020).
https://www.bloomberg.com/opinion/articles/2020-05-11/lowering-coronavirus-infection-average-won-t-stop-all-spread
------------------------------
Date: 17 May 2020 15:18:05 -0400
From: "John Levine" <
johnl@iecc.com>
Subject: Re: Stimulus check delays when accounts were overdrawn! (RISKS-31.83)
This article misses the key point that for the most part the entire US tax preparation industry is predatory and unnecessary.
For people with simple tax returns, which likely includes everyone described
in that article, the IRS (the tax authority) already has enough information
to prepare their returns. The IRS could send you a tentative return, you say it's OK or make corrections, and send it back and you're done. I gather this
is common in other countries. (There aren't a lot of new privacy issues
here, since this is the same info they already have to check that the return you file is correct.)
The commercial tax prep industry knows this and has been fighting for
decades to keep it from happening. Since it's hard to make a persuasive argument for why people should pay private tax prep for a service the government can do better for free, there has been a great deal of smoke and mirrors and "compromises." The current compromise is that eight of the commercial tax preparers have a free online version you can use if your
income is below a threshold ($69K for most of them) and otherwise simple,
and if you know about it and you can find this link on the IRS web site:
https://apps.irs.gov/app/freeFile/
In a scandal last year, one of the prep companies had a different "free"
site which charged for most returns, and coded their web pages to hide the
real free site from search engines. In fact only about 3% of the US
taxpayers eligible to use free file do so.
The people described in the article also all sound like they'd have been eligible to use free file and get 100% of their refund and their Corona
payment directly into their own accounts, had they known about it. If the
tax prep companies were honest they'd tell people you don't need to pay us,
you can get our service for free online, but fat chance.
Beyond that are the issues of all the ways the tax prep companies prey on
their customers so they don't get the money they should, but the article described that pretty well.
------------------------------
Date: Sun, 17 May 2020 02:27:00 -0400
From: David <
wb8foz@panix.com>
Subject: Re: Coronavirus New York Shock: Two-Thirds Of Recent Patients
Infected While Staying At Home (Elinsky, RISKS-31.83)
Besides the very real fire issue, you also some have residents smoking,
cooking lutefisk, etc. And sound transmission between units.
But more important to the builder, those required large ducts will be non-revenue space, the last thing any developer wants. Far smaller pipes
will carry equal KW's of heating/cooling.
------------------------------
Date: Sun, 17 May 2020 06:57:45 +0900
From: "ISHIKAWA,chiaki" <
ishikawa@yk.rim.or.jp>
Subject: Re: Meaningless "review" of Imperial COVID codebase (RISKS-31.83)
Meaningless "review" of Imperial COVID codebase (Wordpress)
Although I generally agree with that assessment, there *ARE* problems with Imperial code.
- The lack of reproducibility: Even with a simulation program,
reproducibility using the same series of pseudo-random numbers is very important for verification/debugging. Imperial code does not seem to have
it. I think the lack of reproducibility on the same hardware seems to be caused by the following bug.
- Memory access errors: I notice a few git patches mentioned in
https://lockdownsceptics.org/code-review-of-fergusons-model/ and/or articles that can be reached from it, that there are uninitialized memory accesses,
and possibly out of bound memory accesses. Very bad. Anything goes with the code before the fixes when the outcome of the program was used to estimate
the # of infections and possibly deaths in UK.
I feel it would be interesting to see current release of Imperial code run under valgrind/memcheck memory access checker. I suspect MS programmers realized these issues right away when they had access to the about-to-be-released Imperial code using some internal tool.
I think the lack of reproducibility using the same series of pseudo random numbers on the SAME HARDWARE poses great doubt on the correctness of the Imperial code. There *may be* genuine logic error(s) or random errors
caused by incorrect memory access. GIGO.
If the above issues are fixed, ONLY THEN we can begin to evaluate Imperial
code in terms of evaluation metrics in the expert field, in this case epidemiology.
My credential: Trained as a physics student who used to write lousy code
from the viewpoint enterprise software developer. Now I have been working
as software developer for quite some time. So I can tell I WROTE CORRECT BUT LOUSY CODE when I was grad student.:-)
Anecdotal evidence about scientist's writing CORRECT BUT LOUSY code from the viewpoint of software developers.
Stephen Wolfram of Mathematica fame, was a physicist by education. He
received Ph.D. from Caltech in 1979. He was interested in cellular automata for a while in the 1980/1990's to study bifurcation caused by some such automata when their behavior is plotted on computer screen (as in LIFE
game), and wrote a code that simulates such automata behavior. I can't
recall the name of the exact program, but his program source file was
included in Sun Microsystems User Group software tape (not floppy, not CD,
but magnetic tape back then.) I was already a software developer after quitting my grad study when I noticed Wolfram's name in the list of the programs (he had already been known for a symbolic manipulation system, a precursor of Mathematica of a sort), I looked at the code. I was
horrified. It was a C code, but the indentation was horrible. And there WERE compiler warnings when I tried to compile it. I wonder where Wolfram
learned C programming. It was written as if the code was, hmm, Fortran. No indentation. All source code lines started on the first column. No type
safety. Pointers were stored in integers and vice versa (it was OK on a byte-addressable 32 bit computers. But my experience with Data General
Eclipse 32-bit computer with word-addressable operation mode, the mixing of pointers and integers was a no no.). BUT important point here is that his program WAS a CORRECT program on Sun hardware that simulates cellular
automata that behaves according to some parameters based on user input and
not only that, it plots the behavior of cells on then Sun workstation's
black and white screen using sunview toolkit. The horrible indentation
could be simply improved by running the source code through |indent|
program, and after throwing some type casts to shut up compiler warnings, it was easy to verify that the code did what it was advertised to do correctly.
My point here is that the LOUSY looking code Wolfram wrote was CORRECT.
I don't think we can say that for Imperial code before the heavy bug fixes visible at github. I would say there had been a GIGO situation.
Another anecdotal evidence about the rigor necessary for software used in academic work.
When supernova 1987A generated a flurry of neutrinos that reached the solar system, some of them were observed by Japanese underground neutrino
detector, called Kamiokande. The research crew never saw such clusters of neutrinos, but learning of 1987A was observed in the southern hemisphere
(not visible from Japan), they figured that the neutrinos may be from the supernovae traveling through the earth from the southern sky. The research facility's program never meant to detect something from the invisible
southern sky. So the researchers including graduate students decided to
create a quick program to see if the direction of the incidental neutrinos match that of 1987A. It did. They wrote a paper about the observation
quickly and it was sent out by airmail. (It was before the Internet.) After the envelope was handed over to the counter at the post office near the main gate of the U. of Tokyo, someone at the Koshiba lab which manages Kamiokande realized there was an incorrect sign (+/-) used in a formula to calculation
of the direction. I think someone forgot that they needed now to look DOWN toward the southern hemisphere instead of looking UP at the northern
hemisphere sky. The recalculation using the corrected formula was done, and luckily the conclusion was the same. However, Prof. Koshiba (later Nobel laureate) rushed to the post office and demanded to see the office chief to retrieve the envelope already in the possession of the post office and
replaced the paper with a corrected formula. The rest is history. I think
in today's culture, the initial paper reaches the office of Physical Review
and quickly be replaced with a revised version, etc. The retrieving of envelope at the post office is a bit embarrassing story both for
Prof. Koshiba AND the post office chief of that time, but Prof. Koshiba
talked about this in public, which was later published, I think it is OK for
me to quote it.
I am afraid that the authors of Imperial code lacked the rigor to verify the original code operation and correctness of it using whatever correctness criteria they may have in mind. I sense this lack of rigor based on the failure to achieve reproducibility (as I suspect may be due to the incorrect memory access.). When there is no reproducibility, how can one expect to be confident of the "correctness" of simulation?
OTOH, I commend that the code albeit with dubious history (it may not
reflect the original code at all) is made available to the public. This
makes scientific scrutiny possible after all.
------------------------------
Date: Mon, 14 Jan 2019 11:11:11 -0800
From:
RISKS-request@csl.sri.com
Subject: Abridged info on RISKS (comp.risks)
The ACM RISKS Forum is a MODERATED digest. Its Usenet manifestation is
comp.risks, the feed for which is donated by panix.com as of June 2011.
SUBSCRIPTIONS: The mailman Web interface can be used directly to
subscribe and unsubscribe:
http://mls.csl.sri.com/mailman/listinfo/risks
SUBMISSIONS: to risks@CSL.sri.com with meaningful SUBJECT: line that
includes the string `notsp'. Otherwise your message may not be read.
*** This attention-string has never changed, but might if spammers use it.
SPAM challenge-responses will not be honored. Instead, use an alternative
address from which you never send mail where the address becomes public!
The complete INFO file (submissions, default disclaimers, archive sites,
copyright policy, etc.) is online.
<
http://www.CSL.sri.com/risksinfo.html>
*** Contributors are assumed to have read the full info file for guidelines!
OFFICIAL ARCHIVES: http://www.risks.org takes you to Lindsay Marshall's
searchable html archive at newcastle:
http://catless.ncl.ac.uk/Risks/VL.IS --> VoLume, ISsue.
Also,
ftp://ftp.sri.com/risks for the current volume
or
ftp://ftp.sri.com/VL/risks-VL.IS for previous VoLume
If none of those work for you, the most recent issue is always at
http://www.csl.sri.com/users/risko/risks.txt, and index at /risks-31.00
Lindsay has also added to the Newcastle catless site a palmtop version
of the most recent RISKS issue and a WAP version that works for many but
not all telephones:
http://catless.ncl.ac.uk/w/r
ALTERNATIVE ARCHIVES:
http://seclists.org/risks/ (only since mid-2001)
*** NOTE: If a cited URL fails, we do not try to update them. Try
browsing on the keywords in the subject line or cited article leads.
Apologies for what Office365 and SafeLinks may have done to URLs.
Special Offer to Join ACM for readers of the ACM RISKS Forum:
<
http://www.acm.org/joinacm1>
------------------------------
Date: Sun, 17 May 2020 10:07:40 -0700
From: Henry Baker <
hbaker1@pipeline.com>
Subject: Re: Meaningless "review" of Imperial COVID codebase (RISKS-31.83)
Following Fermat, there isn't enough space in this margin to fully address
the problems in Covid models, but I will list some *major* issues:
1. Differential equation models -- e.g., Ross/Kermack-McKendrick -- the original "R0"/"R_nought" models. Problem: there may be *no* reasonable
single estimate of R0, as the variance in R0 may be exceedingly large --
e.g., "super-spreaders" who infect 50-100 people. *Fractals* and *fat
tails* and *fragility*, oh my! Oops!
2. Monte Carlo models. By definition, epidemics depend upon *positive feedback loops* which produce *exponential behavior*. Such exponential behavior guarantees that the system is *ill- conditioned*, hence minuscule differences in inputs -- e.g., noise or round-off errors -- produce dramatic and/or overwhelming differences in results: garbage-in, garbage-out.
E.g., suppose that you use your Monte Carlo method to compute N independent samples of a random variable X in order to estimate mean(X). Then var(avg(X_i)) = var(X)/N. But what if var(X) is extremely large and/or infinite ? Then N has to also be exceedingly large and/or infinite, else
*no convergence*, hence garbage answer! Oops!
Once again, policies having *trillion-dollar* effects should require substantially better and more perspicuous models than the Imperial Covid-Sim model.
------------------------------
Date: Mon, 18 May 2020 09:16:04 +0930
From: William Brodie-Tyrrell <
william.brodie.tyrrell@gmail.com>
Subject: Re: NOTSP Re: Meaningless "review" of Imperial COVID codebase
(Baker, RISKS-31.84)
Again, this criticism is all true but entirely misses the point and purpose
of these models. Their purpose is not to say "this will be the exact
outcome" -- which is impossible because critical and sensitive inputs are not measurable accurately - but to predict the relative impact and effectiveness
of public policy controls.
If the model predicts 1M fatalities with no action and 10k fatalities with specific controls in place, that is the desired outcome: it provides some evidence that the control should be enacted. Absolutely no one cares -
except people who try to look smart by "reviewing" code and models outside
of their domain - that the true answer was either 700k or 2M fatalities
without the control in-place.
Controls and environmental factors and human behaviours are
constantly-changing during an epidemic and no epidemiologist pretends that their model is precisely predicting outcomes, so yay for setting fire to yet another strawman I guess?
------------------------------
Date: Sun, 17 May 2020 21:31:53 -0700
From: Henry Baker <
hbaker1@pipeline.com>
Subject: Re: Meaningless "review" of Imperial COVID codebase (RISKS-31.84)
What about *garbage out* can't you comprehend?
Please Google "ill-conditioned" and see me in the morning.
You keep presuming that these models output useful information because they *happen to* produce graphs that are sometimes reminiscent of actual data.
I have some cheese mold that *happens to* look like a picture of Jesus. So what?
A "model" can't predict *anything* when it outputs *zero* significant bits.
Such an ill-conditioned model can't even get the *order of magnitude* of the *exponent* right.
------------------------------
End of RISKS-FORUM Digest 31.84
************************
--- SoupGate-Win32 v1.05
* Origin: fsxNet Usenet Gateway (21:1/5)
{kind=link}
{kind=link}