I have a series of one-page PDFs that are really images and not text even >though they look like they're just a page of simple text in the same font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
I have a series of one-page PDFs that are really images and not text even though they look like they're just a page of simple text in the same font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
On 7/13/2024 8:46 PM, Bill Powell wrote:
I have a series of one-page PDFs that are really images and not text even
though they look like they're just a page of simple text in the same font. >>
Is there a way to easily OCR a PDF to actual text on Windows for free?
I have a program called FreeOCR that will do it without having to scan
or extract the pages. Quality depends on fonts, words, etc, but general
it comes out well.
Is there a way to easily OCR a PDF to actual text on Windows for free?
I have a program called FreeOCR that will do it without having to scan
or extract the pages. Quality depends on fonts, words, etc, but general
it comes out well.
Is there a way to easily OCR a PDF to actual text on Windows for free?
Aren't there lots of websites that do this, but you have to upload the
file. I've resisted that but would be really happpy if I could do it
inside my computer.
I have a series of one-page PDFs that are really images and not text even >though they look like they're just a page of simple text in the same font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
On 7/13/2024 8:46 PM, Bill Powell wrote:
I have a series of one-page PDFs that are really images and not text even
though they look like they're just a page of simple text in the same
font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
� I have a program called FreeOCR that will do it without having to scan
or extract the pages. Quality depends on fonts, words, etc, but general
it comes out well.
I have a series of one-page PDFs that are really images and not text even though they look like they're just a page of simple text in the same font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
On Sun, 14 Jul 2024 02:46:04 +0200, Bill Powell <bill@anarchists.org>
wrote:
I have a series of one-page PDFs that are really images and not text even >though they look like they're just a page of simple text in the same font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
Windows Power Toys - Text extractor.
In alt.comp.os.windows-10, on Sat, 13 Jul 2024 22:22:11 -0400, Newyana2 <newyana@invalid.nospam> wrote:
On 7/13/2024 8:46 PM, Bill Powell wrote:
I have a series of one-page PDFs that are really images and not text even >>> though they look like they're just a page of simple text in the same font. >>>
Is there a way to easily OCR a PDF to actual text on Windows for free?
I have a program called FreeOCR that will do it without having to scan
or extract the pages. Quality depends on fonts, words, etc, but general
it comes out well.
http://www.freeocr.net/
http://www.paperfile.net/ https://www.google.com/search?client=firefox-b-1-d&q=FreeOCR--
I have a series of one-page PDFs that are really images and not text even though they look like they're just a page of simple text in the same font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
On 14.07.2024 02:46, Bill Powell wrote:
I have a series of one-page PDFs that are really images and not text even
though they look like they're just a page of simple text in the same
font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
For only a few lines of text you can use the Snipping Tool: press <WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
Or you can use Firefox to display the pdf and and use an OCR
plug-in.
Several pointers embedded at the URL above elicit "blacklisted site"
messages from AVG.
And I'm sure there are other free PDF viewers that have OCR
capability, though PDF-Xchange is the only one I use.
On 7/14/2024 2:35 AM, Jeff Barnett wrote:
Several pointers embedded at the URL above elicit "blacklisted site"
messages from AVG.
I should have posted the URL. freeocr.net is just a listing site.
paperfile.net is the host of FreeOCR.
I researched this awhile back. I'd been using something that I'd got
from a magazine CD in the late 90s and it actually worked pretty well. >Textbridge Pro. (Along with Lotus WordPro 95. Those magazine CDs
served me well.)
But I decided to look around for something more up-to-date because
I sometimes want to convert things like photo-PDFs to plain text.
FreeOCR seems to be simple, quick and no-nonsense. It saves the step
of having to extract images from PDFs. The only down
side is that it came out in early Win10 days and it has a kiddie interface >with a silly fading window at close, with no option to change that. >However... it might be Fischer-Price, but it works. :)
There's an explanation at the site. If I remember correctly, the system
it uses is OSS and while there are newer versions, I didn't find anything >else that was all put together. What I mean is that you can find more recent >updates of the Tesseract OCR code, https://github.com/tesseract-ocr,
but it's OSS that's hard to find as finished software.
The program seems to be a fairly simple .Net wrapper around a compiled
EXE version of Tesseract, but it's well designed, making Tesseract usable
and convenient.
I use Irfanveiw for all my image and OCR projects.
You need Irfanview and the OCR plugin.
Open the PDF file in Irfanvieiw, high lite the text and activate the
OCR function.
And I'm sure there are other free PDF viewers that have OCR
capability, though PDF-Xchange is the only one I use.
I also use PDFXV free and love it. I had to get a new version
for Win10. Build 322.10. Lucky it was stil available free. My older
version on XP didn't work right on 10.
� I have a program called FreeOCR that will do it without having to scan
or extract the pages. Quality depends on fonts, words, etc, but general
it comes out well.
+1
There is a GNU OCR engine called "GOCR" (or sometimes JOCR) out there. https://jocr.sourceforge.net/
There's no mention it uses the modern Tesseract scan engine though.
I should have posted the URL. freeocr.net is just a listing site. >>paperfile.net is the host of FreeOCR.
And it doesn't mention win10 or 11. I can assume you've been using it
with one of those two.
I thought of just installing it to see if it works, but who knows, maybe installing old, no longer compaitble software could mess up my OS??
Windows Power Toys - Text extractor.
You forgot to give the URL: https://learn.microsoft.com/en-us/windows/powertoys/text-extractor
That one says it's "based on Joe Finney's TextGrab", and links to https://github.com/TheJoeFin/Text-Grab
Has anyone tried both, and can speak to whether one does a better job
of text extraction than the other?
W Sat, 13 Jul 2024 22:58:17 -0700, Stan Brown napisal:Years ago I used and really liked Kingsoft. Then LibreOffice got better and I switched. But
Windows Power Toys - Text extractor.
You forgot to give the URL:
https://learn.microsoft.com/en-us/windows/powertoys/text-extractor
That one says it's "based on Joe Finney's TextGrab", and links to
https://github.com/TheJoeFin/Text-Grab
Has anyone tried both, and can speak to whether one does a better job of text extraction than the
other?
I've tried something similar to Microsoft Office for OCR on Windows.
What I tried was a MS Office clone called WPS Office, which I found here. https://www.wps.com/office/pdf/
The company appears to be "Kingsoft" and their webstubb installer is here. https://wdl1.pcfg.cache.wpscdn.com/wpsdl/wpsoffice/onlinesetup/distsrc/600.1022/wpsinst/wps_office_inst.exe
Name: wps_lid.lid-u8MZl7zT7a0C.exe
Size: 5864848 bytes (5727 KiB)
SHA256: 81E09F93F6B1C7F9488D912CFD82560D978262CB75ECF7B7953403A8A706259B
Since that looks scary, I ran it by a virustotal which cleared it clean. https://www.virustotal.com/gui/file/81e09f93f6b1c7f9488d912cfd82560d978262cb75ecf7b7953403a8a706259b
You have to be careful as it will change your PDF defaults.
Select "Custom Settings" (not "Install Now").
Change from:
[x] Use WPS Office to open pdf files by default
[x] Use WPS Office as the default program for documents
[x] Use WPS Photos to open JPG, PNG, and other image formats by default
Change to:
[_] Use WPS Office to open pdf files by default
[_] Use WPS Office as the default program for documents
[_] Use WPS Photos to open JPG, PNG, and other image formats by default
Then hit the big blue "Install Now" button.
It will say "Downloading WPS Office" so you know it was just a stub.
It will create a wps_download directory containing:
Name: 132ca6c802422ed94a59d10cbcc9f47b-15_setup_XA_mui_Free.exe.600.1022.exe Size: 244193632 bytes (232 MiB)
SHA256: B6B462DCDA4578D716E207D9747D391597110EC8F4A22C9AC29417E68A86A525
After taking forever downloading & installing WPS Office,
WPS Office will try to trick you into installing "360 Total Security".
Do not select the box [_]Yes, I agree to install 360 Total Security...
Click the big blue box "Get Started with WPS".
Start WPS Office and click away the sell-up advertising.
Tools > PDF OCR > Select File > filename.pdf > Perform OCR > Sign in
You have to sign in to what in order to convert a PDF to OCR with WPS.
I guess in the end it's maybe an online converter - but it's hard to tell.
I didn't create an account so I never was able to find out how it works.
All I know is it's a Microsoft Office clone that says it does OCR for free.
Download PDF-XChange Editor/Plus (32/64 Bit Version) (as ZIP File)
Download PDF-XChange Editor PORTABLE (32/64 Bit Version) (as ZIP File) >Download PDF-XChange Editor PORTABLE ohne OCR (32/64 Bit Version) (as ZIP File)
It says "ohne OCR". What does "ohne" mean anyway?
On Sun, 14 Jul 2024 06:54:16 -0400, knuttle wrote:
I use Irfanveiw for all my image and OCR projects.
You need Irfanview and the OCR plugin.
Open the PDF file in Irfanvieiw, high lite the text and activate the
OCR function.
Nice! Once you figure it out, Irfanview with the plugin is great!
I opened a scanned-page bitmap PDF image in Irfanview.
Irfanview:File > Open > scan.jpg
Irfanview:Options > Start OCR...(Plugin)
This opened up the page of bitmap text in yellow highlight at the left.
I have a series of one-page PDFs that are really images and not text even though they look like they're just a page of simple text in the same font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
On 14.07.2024 02:46, Bill Powell wrote:
I have a series of one-page PDFs that are really images and not text even though they look like they're just a page of simple text in the same font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
For only a few lines of text you can use the Snipping Tool: press <WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
I use Irfanveiw for all my image and OCR projects.
You need Irfanview and the OCR plugin.
Open the PDF file in Irfanvieiw, high lite the text and activate the
OCR function.
Enrico Papaloma wrote:
Download PDF-XChange Editor/Plus (32/64 Bit Version) (as ZIP File)
Download PDF-XChange Editor PORTABLE (32/64 Bit Version) (as ZIP File) >Download PDF-XChange Editor PORTABLE ohne OCR (32/64 Bit Version) (as ZIP File)
It says "ohne OCR". What does "ohne" mean anyway?
Ohne is German,meaning "without".
On Sun, 14 Jul 2024 09:25:09 +0200, Herbert Kleebauer wrote:
On 14.07.2024 02:46, Bill Powell wrote:
I have a series of one-page PDFs that are really images and not text even >>> though they look like they're just a page of simple text in the same font. >>>
Is there a way to easily OCR a PDF to actual text on Windows for free?
For only a few lines of text you can use the Snipping Tool: press
<WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
What OCR function? I just get a menu at the top of the screen
consisting of five icons: Rectangular snip, Freeform snip, Window
snip, Fullscreen snip, Close snipping.
For only a few lines of text you can use the Snipping Tool: press
<WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
What OCR function? I just get a menu at the top of the screen
consisting of five icons: Rectangular snip, Freeform snip, Window
snip, Fullscreen snip, Close snipping.
the page of bitmap text in yellowAfter you have highlighted the text and started the OCR plug in, you
On 15.07.2024 22:09, Stan Brown wrote:
For only a few lines of text you can use the Snipping Tool: press
<WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
What OCR function? I just get a menu at the top of the screen
consisting of five icons: Rectangular snip, Freeform snip, Window
snip, Fullscreen snip, Close snipping.
Maybe it is only available in Win11 but not in Win10.
I have version: Snipping Tool 11.2405.32.0
https://support.microsoft.com/en-us/windows/use-snipping-tool-to-capture-screenshots-00246869-1843-655f-f220-97299b865f6b#ID0EDD=Windows_11
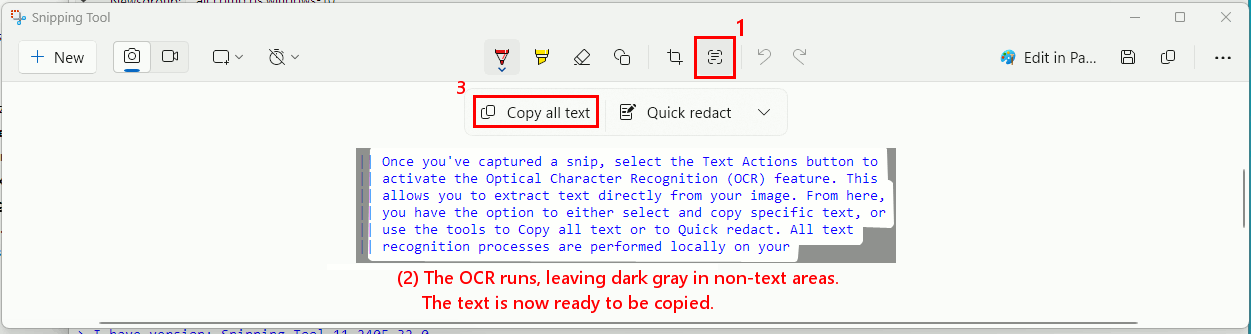
|| Once you've captured a snip, select the Text Actions button to
|| activate the Optical Character Recognition (OCR) feature. This
|| allows you to extract text directly from your image. From here,
|| you have the option to either select and copy specific text, or
|| use the tools to Copy all text or to Quick redact. All text
|| recognition processes are performed locally on your
The "Copy as Text" is presumably supposed to trigger "OCR was done"
in your brain ??? A violation of discover-ability. Or of some other
principle they might have taught in CS school.
On 15.07.2024 22:09, Stan Brown wrote:
For only a few lines of text you can use the Snipping Tool: press
<WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
What OCR function? I just get a menu at the top of the screen
consisting of five icons: Rectangular snip, Freeform snip, Window
snip, Fullscreen snip, Close snipping.
Maybe it is only available in Win11 but not in Win10.
I have version: Snipping Tool 11.2405.32.0
mandag, 15-07-2024, Stan Brown skrev:
On Sun, 14 Jul 2024 09:25:09 +0200, Herbert Kleebauer wrote:
On 14.07.2024 02:46, Bill Powell wrote:
I have a series of one-page PDFs that are really images and not text even >>> though they look like they're just a page of simple text in the same font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
For only a few lines of text you can use the Snipping Tool: press
<WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
What OCR function? I just get a menu at the top of the screen
consisting of five icons: Rectangular snip, Freeform snip, Window
snip, Fullscreen snip, Close snipping.
Select Rectangular snip, select the text, double click on Snipping
Tools, click on text in the menu, select the text and copy.
On 07/14/2024 3:25 AM, Herbert Kleebauer wrote:
On 14.07.2024 02:46, Bill Powell wrote:I use Irfanveiw for all my image and OCR projects.
I have a series of one-page PDFs that are really images and not text
even
though they look like they're just a page of simple text in the same
font.
Is there a way to easily OCR a PDF to actual text on Windows for free?
For only a few lines of text you can use the Snipping Tool: press
<WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
Or you can use Firefox to display the pdf and and use an OCR
plug-in.
You need Irfanview and the OCR plugin.
Open the PDF file in Irfanvieiw, high lite the text and activate the
OCR function.
On 15.07.2024 22:09, Stan Brown wrote:
For only a few lines of text you can use the Snipping Tool: press
<WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
What OCR function? I just get a menu at the top of the screen
consisting of five icons: Rectangular snip, Freeform snip, Window
snip, Fullscreen snip, Close snipping.
Maybe it is only available in Win11 but not in Win10.
I have version: Snipping Tool 11.2405.32.0
https://support.microsoft.com/en-us/windows/use-snipping-tool-to-capture-screenshots-00246869-1843-655f-f220-97299b865f6b#ID0EDD=Windows_11
I recently had to sort out an XP machine with some 500 wrongly named & >corrupted files that contained photos.
I was pleasantly surprised at the number of different types of file that >Irfanview would open, play & sort out the correct extension. Save me
hundreds of clicks & hours of work.
On Mon, 15 Jul 2024 23:01:24 +0200, Herbert Kleebauer wrote:
On 15.07.2024 22:09, Stan Brown wrote:
For only a few lines of text you can use the Snipping Tool: press
<WIN><SHIFT>S and select the part of the screen with the text.
When the Snipping Tool opens, select the OCR function.
I did mot write the above paragraph.
What OCR function? I just get a menu at the top of the screen
consisting of five icons: Rectangular snip, Freeform snip, Window
snip, Fullscreen snip, Close snipping.
Maybe it is only available in Win11 but not in Win10.
I have version: Snipping Tool 11.2405.32.0
Oh, silly me. We're in a Windows 10 newsgroup, so I thought we were
talking about a Windows 10 feature.
I recently had to sort out an XP machine with some 500 wrongly named & >>corrupted files that contained photos.
I was pleasantly surprised at the number of different types of file that >>Irfanview would open, play & sort out the correct extension. Save me >>hundreds of clicks & hours of work.
I find Irfanview very useful for all kinds of graphics tasks.
In alt.comp.os.windows-10, on Sun, 14 Jul 2024 02:46:04 +0200, Bill
Powell <bill@anarchists.org> wrote:
I have a series of one-page PDFs that are really images and not text even
though they look like they're just a page of simple text in the same font. >>
Is there a way to easily OCR a PDF to actual text on Windows for free?
Aren't there lots of websites that do this, but you have to upload the
file. I've resisted that but would be really happpy if I could do it
inside my computer.
On 14/07/2024 02:57, micky wrote:
In alt.comp.os.windows-10, on Sun, 14 Jul 2024 02:46:04 +0200, Bill
Powell <bill@anarchists.org> wrote:
I have a series of one-page PDFs that are really images and not text even >>> though they look like they're just a page of simple text in the same font. >>>
Is there a way to easily OCR a PDF to actual text on Windows for free?
Aren't there lots of websites that do this, but you have to upload the
file. I've resisted that but would be really happpy if I could do it
inside my computer.
Is tesseract not available on Windows?
P
| Sysop: | Keyop |
|---|---|
| Location: | Huddersfield, West Yorkshire, UK |
| Users: | 361 |
| Nodes: | 16 (2 / 14) |
| Uptime: | 123:26:04 |
| Calls: | 7,716 |
| Files: | 12,861 |
| Messages: | 5,727,955 |
{kind=link}